
ESPGOAL
A Dependency Driven Communication Framework
Introduction
The demand for parallel computing continues to rise as a lot of researchers depend on fine-grained simulations or the solution of large systems of differential equations. The hardware available to perform such computations is becoming faster and cheaper. However, increasing the clock frequency of processors is limited by constraints such as power dissipation. So systems are not getting much faster but more parallel since many years.
Utilizing a huge number of cores in message passing frameworks such as MPI has been shown to be difficult when point to point messaging is used for communication. It obfuscates the communication pattern, complicates the design and implementation of parallel programs and hinders performance in some cases. To develop scalable scientific applications, collective communication should be used instead.
Collectives in MPI-2 are blocking, which means communication can not be overlapped by computation. This is expected to change in the future, as non-blocking implementations of MPI collectives, such as LibNBC have been shown to improve the performance of scientific applications.
Two main problems have been identified when using
non-blocking MPI collectives. The first problem is progression:
When a non-blocking MPI collective is executed and its
execution is overlapped with computation there must be a way to
ensure that the communication can progress. For user level MPI
libraries this can be done in two ways: either the computation
has to be interleaved with calls to the MPI library such as
MPI_Test(), or the communication has to be
performed in a separate thread. Both options have drawbacks:
The optimal frequency for the polling is hard to determine and
depends on machine and network parameters such as interrupt and
network latency. Also it can be impossible to split the
computation into smaller pieces to interleave it with test
calls, for example when the computation step is a call to an
external library.
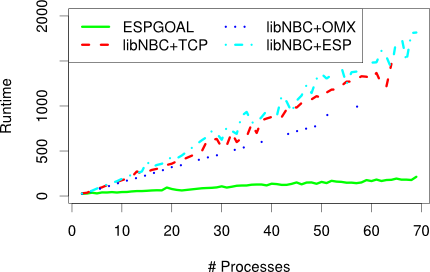
The progression problem could be solved completely by making the network interface hardware or a part of the software network stack aware of the abstract communication pattern that should be executed so that progression does not have to be ensured by the application. ESPGOAL is implemented as a Linux kernel module, as such it can implement asynchronous progression without polling as it can receive notifications from the Linux kernel network stack whenever new data has arrived. Due to the event-based progression scheme, the CPU overhead incurred by ESPGOAL when executing collective operations is much lower than that of LibNBC.

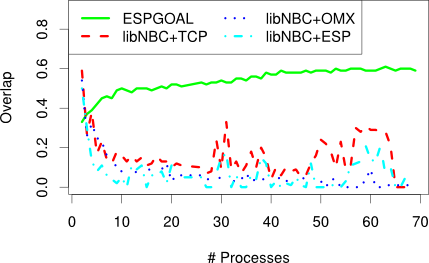
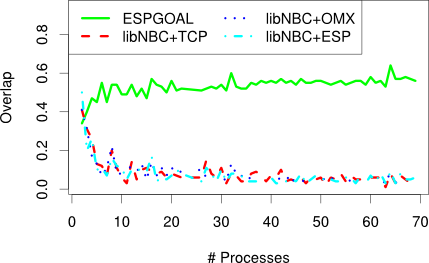
We also measured the fraction of the collective operations latency that could be overlapped with computation.
Another problem with MPI collectives is that the application can not define new collectives dynamically. ESPGOAL solves this problem as it can execute arbitrary communication patterns. Communication is described in ESPGOAL with the primitives send, recv and predefined reduction operators, as well as dependencies between them. The idea to express collective communication tasks as dependency graphs was published in [1]. With ESPGOAL the user can build dependency DAGs with a simple C-library interface. If the user is finished building the communication schedule, the graph is stored in a compressed binary format and transferred to the kernel. The kernel then executes the schedule, independently from the user application. The complete control flow is shown below.
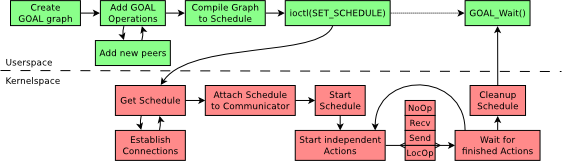
To carry out the send and receive operations specified in the schedule, our kernel leverages a modified version of the Ethernet Stream Protocol.
More detailed information about ESPGOAL can be found in the student research project report [3].
Source Code
Bibliography
-
- T. Hoefler, C. Siebert and A. Lumsdaine
- Group Operation Assembly Language - A Flexible Way to Express Collective Communication In ICPP-2009 - The 38th International Conference on Parallel Processing, presented in Vienna, Austria, IEEE, ISBN: 978-0-7695-3802-0, Sep. 2009
Publications
-
- T. Schneider, S. Eckelmann, T. Hoefler and Wolfgang Rehm
- Kernel-Based Offload of Collective Operations -- Implementation, Evaluation and Lessons Learned Accepted for inclusion in the technical program and the proceedings of Euro-Par 2011, Bordeaux, France.. August 2011
-
- T. Schneider and S. Eckelmann
- ESPGOAL - A Dependency Driven Communication Framework Student Research Project Report, Chemnitz University of Technology, Germany, January 2011